In this article, you will learn how to design, implement, and evaluate memory systems that make agentic AI applications more reliable, personalized, and effective over time.
Topics we will suggest:
1) Why memory should be treated as a systems design problem rather than just a larger-context-model problem.
2) The main memory types used in agentic systems and how they map to practical architecture choices.
3) How to retrieve, manage, and evaluate memory in production without polluting the context window.
Introduction
Memory is one of the most overlooked parts of agentic system design. Without memory, every agent run starts from zero — with no knowledge of prior sessions, no recollection of user preferences, and no awareness of what was tried and failed an hour ago. For simple single-turn tasks, this is fine, but for agents running and coordinating multi-step workflows, or serving users repeatedly over time, statelessness becomes a hard ceiling on what the system can actually do.
Memory lets agents accumulate context across sessions, personalize responses over time, avoid repeating work, and build on prior outcomes rather than starting fresh every time. The challenge is that agent memory isn’t a single thing. Most production agents need short-term context for coherent conversation, long-term storage for learned preferences, and retrieval mechanisms for surfacing relevant memories.
This article covers seven practical steps for implementing effective memory in agentic systems. It explains how to understand the memory types your architecture needs, choose the right storage backends, write and retrieve memories correctly, and evaluate your memory layer in production.
Step 2: Learning the AI Agent Memory Type Taxonomy
Cognitive science gives us a vocabulary for the distinct roles memory plays in intelligent systems. Applied to AI agents, we can roughly identify four types, and each maps to a concrete architectural decision.
Short-term or working memory is the context window — everything the model can actively reason over in a single inference call. It includes the system prompt, conversation history, tool outputs, and retrieved documents. Think of it like RAM: fast and immediate, but wiped when the session ends. It’s typically implemented as a rolling buffer or conversation history array, and it’s sufficient for simple single-session tasks but cannot survive across sessions.
Episodic memory records specific past events, interactions, and outcomes. When an agent recalls that a user’s deployment failed last Tuesday due to a missing environment variable, that’s episodic memory at work. It’s particularly effective for case-based reasoning — using past events, actions, and outcomes to improve future decisions. Episodic memory is commonly stored as timestamped records in a vector database and retrieved via semantic or hybrid search at query time.
Semantic memory holds structured factual knowledge: user preferences, domain facts, entity relationships, and general world knowledge relevant to the agent’s scope. A customer service agent that knows a user prefers concise answers and operates in the legal industry is drawing on semantic memory. This is often implemented as entity profiles updated incrementally over time, combining relational storage for structured fields with vector storage for fuzzy retrieval.
Procedural memory encodes how to do things — workflows, decision rules, and learned behavioral patterns. In practice, this shows up as system prompt instructions, few-shot examples, or agent-managed rule sets that evolve through experience. A coding assistant that has learned to always check for dependency conflicts before suggesting library upgrades is expressing procedural memory.
These memory types don’t operate in isolation. Capable production agents often need all of these layers working together.
Step 3: Knowing the Difference Between Retrieval-Augmented Generation and Memory
One of the most persistent sources of confusion for developers building agentic systems is conflating retrieval-augmented generation (RAG) with agent memory.
RAG and agent memory solve related but distinct problems, and using the wrong one for the wrong job leads to agents that are either over-engineered or systematically blind to the right information.
RAG is fundamentally a read-only retrieval mechanism. It grounds the model in external knowledge — your company’s documentation, a product catalog, legal policies — by finding relevant chunks at query time and injecting them into context. RAG is stateless: each query starts fresh, and it has no concept of who is asking or what they’ve said before. It’s the right tool for “what does our refund policy say?” and the wrong tool for “what did this specific customer tell us about their account last month?”
Memory, by contrast, is read-write and user-specific. It enables an agent to learn about individual users across sessions, recall what was attempted and failed, and adapt behavior over time. The key distinction here is that RAG treats relevance as a property of content, while memory treats relevance as a property of the user.
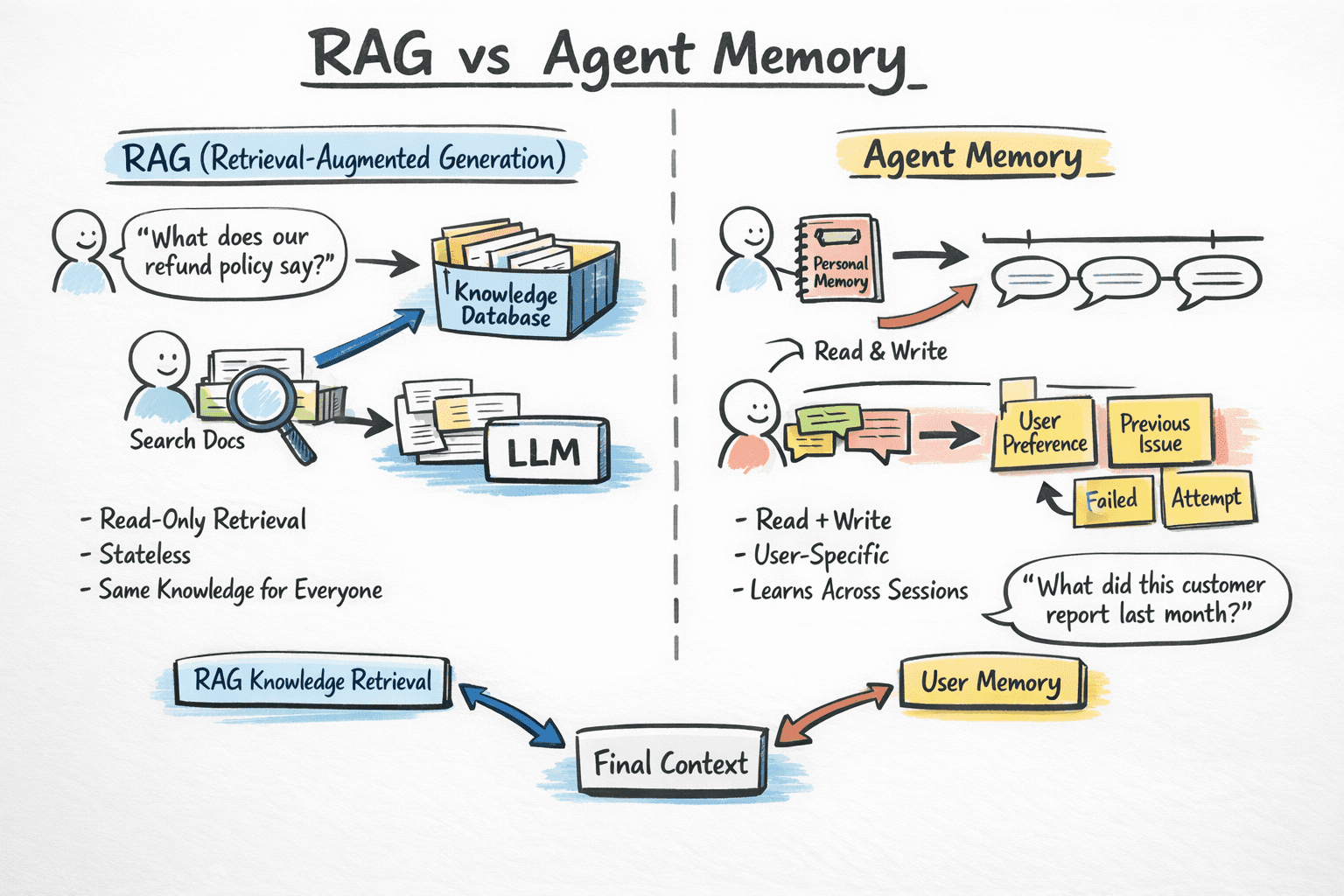
RAG vs Agent Memory | Image by Author
Here’s a practical approach: use RAG for universal knowledge, or things true for everyone, and memory for user-specific context, or things true for this user. Most production agents benefit from both running in parallel, each contributing different signals to the final context window.
Step 4: Designing Your Memory Architecture Around Four Key Decisions
Memory architecture must be designed upfront. The choices you make about storage, retrieval, write paths, and eviction interact with every other part of your system. Before you build, answer these four questions for each memory type:
1. What to Store?
Not everything that happens in a conversation deserves persistence. Storing raw transcripts as retrievable memory units is tempting, but it produces noisy retrieval.
Instead, distill interactions into concise, structured memory objects — key facts, explicit user preferences, and outcomes of past actions — before writing them to storage. This extraction step is where most of the real design work happens.
2. How to Store It?
There are many ways to do this. Here are four primary representations, each with its own use cases:
- Vector embeddings in a vector databaseenable semantic similarity retrieval; they are ideal for episodic and semantic memory where queries are in natural language
- Key-value stores like Redis offer fast, precise lookup by user or session ID; they are well-suited for structured profiles and conversation state
- Relational databases offer structured querying with timestamps, TTLs, and data lineage; they are useful when you need memory versioning and compliance-grade auditability
- Graph databases represent relationships between entities and concepts; this is useful for reasoning over interconnected knowledge, but it is complex to maintain, so reach for graph storage only once vector + relational becomes a bottleneck
3. How to Retrieve It?
Match retrieval strategy to memory type. Semantic vector search works well for episodic and unstructured memories. Structured key lookup works better for profiles and procedural rules. Hybrid retrieval — combining embedding similarity with metadata filters — handles the messy middle ground that most real agents need. For example, “what did this user say about billing in the last 30 days?” requires both semantic matching and a date filter.
4. When (and How) to Forget What You’ve Stored?
Memory without forgetting is as problematic as no memory at all. Be sure to design the deletion path before you need it.
Memory entries should carry timestamps, source provenance, and explicit expiration conditions. Implement decay strategies so older, less relevant memories don’t pollute retrieval as your store grows.
Here are two practical approaches: weight recent memories higher in retrieval scoring, or use native TTL or eviction policies in your storage layer to automatically expire stale data